

Education
What Is AI Automation? A Plain-English Guide for Business Leaders
·9 min read
For data-intensive organisations, the bottleneck isn't analysis — it's the infrastructure that gets data to the right place in the right format at the right time. Manually maintained ETL processes, fragile point-to-point integrations, and reporting workflows that require human intervention to compile are not just inefficient — they're a competitive liability. We build automated data pipelines that connect your source systems, apply AI-powered data validation and transformation, and deliver clean, accurate data to your analytics, reporting, and operational tools continuously. This is not off-the-shelf connector configuration: we build architecturally sound data infrastructure designed for the volume, complexity, and reliability requirements of organisations that take data seriously.
We treat data pipeline design as an engineering project — starting with your data architecture and working forwards to the automation, not backwards from a tool's capability set.
A production-grade data pipeline infrastructure that keeps your organisation's data accurate, accessible, and actionable without manual intervention.
If your data team spends a significant portion of their time on pipeline maintenance rather than analysis — debugging failed syncs, fixing data quality issues, manually reconciling records between systems — you have an infrastructure problem that's suppressing the value of your analytics capability. If your executive dashboards are refreshed manually because there's no automated feed connecting your source systems to your BI tool, strategic decisions are being made on delayed data. If data anomalies are discovered by business users weeks after they occurred because there's no automated monitoring, your data quality controls have gaps.
We build data pipelines with the rigour of software engineering — version-controlled transformation logic, comprehensive testing against production data volumes, and monitoring that treats data quality as a first-class operational metric. Our use of AI in the pipeline layer is specific and intentional: anomaly detection that learns what normal looks like and flags deviations, intelligent deduplication that handles fuzzy matching beyond exact-string rules, and automated data classification for governance purposes. We work with modern data stack tools and custom API integrations equally, designing the right architecture for your specific volume and complexity requirements.


 AI Workflow Automation
AI Workflow Automation CRM Automation
CRM Automation Email & Marketing Automation
Email & Marketing Automation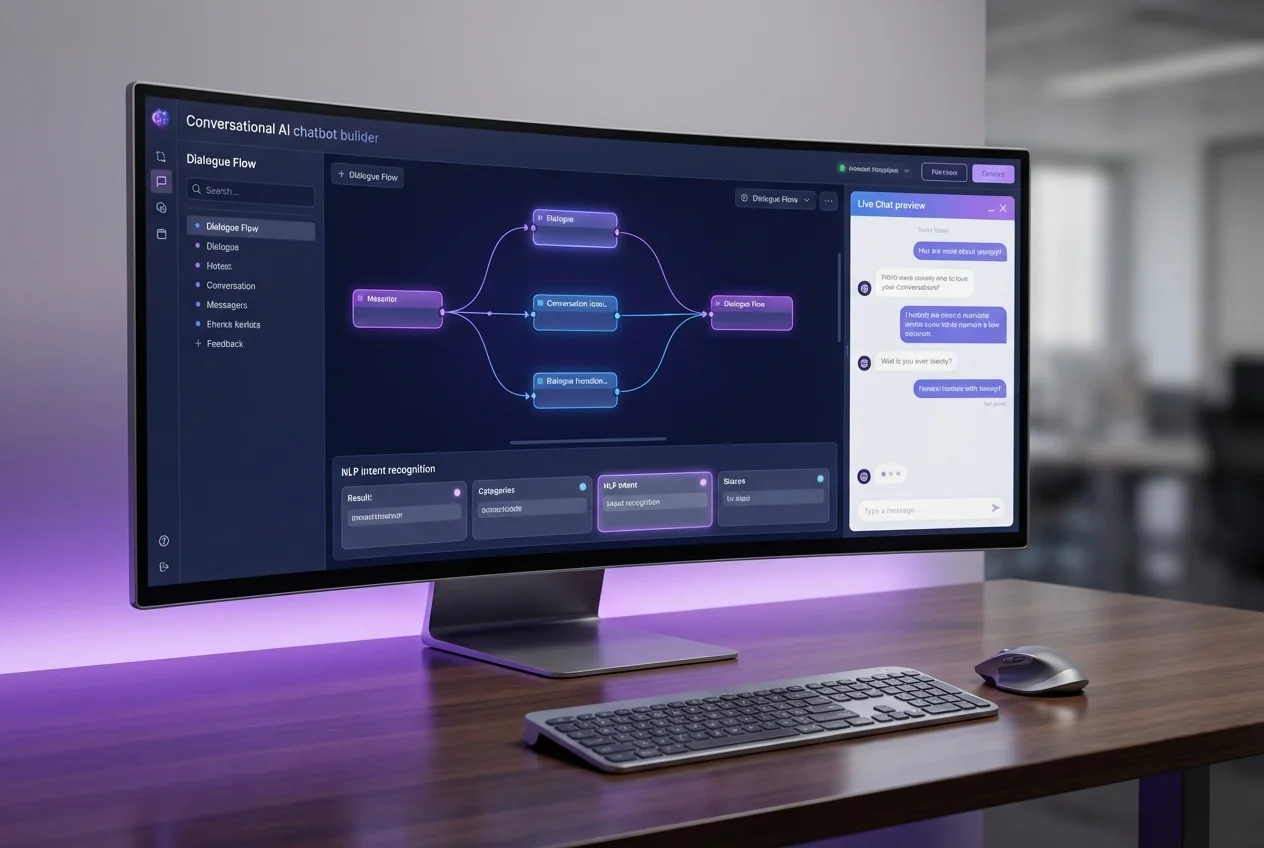 AI Chatbots & Conversational Agents
AI Chatbots & Conversational Agents Automation Strategy & Consulting
Automation Strategy & Consulting